
📌 들어가며
오늘의 학습 목표:
실시간 데이터 스트리밍의 핵심, Apache Kafka를 완벽하게 이해하고 실무에서 바로 활용할 수 있도록 정리하기
안녕하세요! 오늘은 백엔드 개발자라면 꼭 알아야 하는 Apache Kafka에 대해 깊이 있게 학습했습니다. 사실 처음엔 "메시지 큐? 그냥 RabbitMQ랑 비슷한 거 아냐?"라고 생각했는데, 수업을 듣고 나니 Kafka가 단순한 메시지 큐가 아니라 이벤트 스트리밍 플랫폼이라는 걸 확실히 이해하게 되었어요! 💪
특히 실무에서 대용량 트래픽을 처리하거나, 마이크로서비스 간 비동기 통신이 필요할 때 Kafka가 왜 필수인지 체감했습니다. 넷플릭스, 우버, 링크드인 같은 대기업들이 왜 Kafka를 사용하는지 이해가 가더라고요!
🎯 Today I Learned
✅ Apache Kafka란 무엇인가?
✅ Kafka vs 전통적인 메시지 큐 (RabbitMQ, ActiveMQ)
✅ Kafka의 핵심 구성 요소 (Broker, Topic, Partition, Offset)
✅ Producer와 Consumer의 동작 원리
✅ Consumer Group과 리밸런싱
✅ 파티션 전략과 순서 보장
✅ Kafka의 내결함성 (Replication, ISR)
✅ 실무 적용 사례와 Best Practice
🤔 Apache Kafka, 왜 필요할까?
전통적인 시스템의 한계
오늘날의 서비스들은 엄청난 양의 데이터를 실시간으로 처리해야 해요:
❌ 클릭 스트림 데이터: 수백만 사용자의 실시간 활동 추적
❌ 로그 데이터: 서버에서 쏟아지는 수많은 로그
❌ IoT 센서 데이터: 초당 수천 개의 센서 데이터
❌ 금융 거래 데이터: 실시간 주문 처리
기존의 데이터베이스나 메시지 큐로는 이런 대용량 스트리밍 데이터를 감당하기 어려웠어요.
Kafka의 탄생 배경
LinkedIn에서 2011년에 개발했는데, 당시 LinkedIn의 문제는 이거였어요:
문제: 각 시스템이 각자 다른 방식으로 통신
→ 통신 복잡도가 N x N으로 증가
→ 하나의 시스템 변경이 모든 시스템에 영향
해결: Kafka를 중앙 메시징 허브로!
→ 모든 시스템이 Kafka와만 통신
→ 복잡도가 N으로 감소
📊 Apache Kafka란 무엇인가?
Kafka의 정의
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼입니다.
쉽게 말하면:
Kafka = 초대용량 실시간 데이터를 처리하는 파이프라인
A 시스템에서 → Kafka → B, C, D... 모든 시스템으로
동시에 데이터를 전달할 수 있어요!
Kafka vs 전통적인 메시지 큐
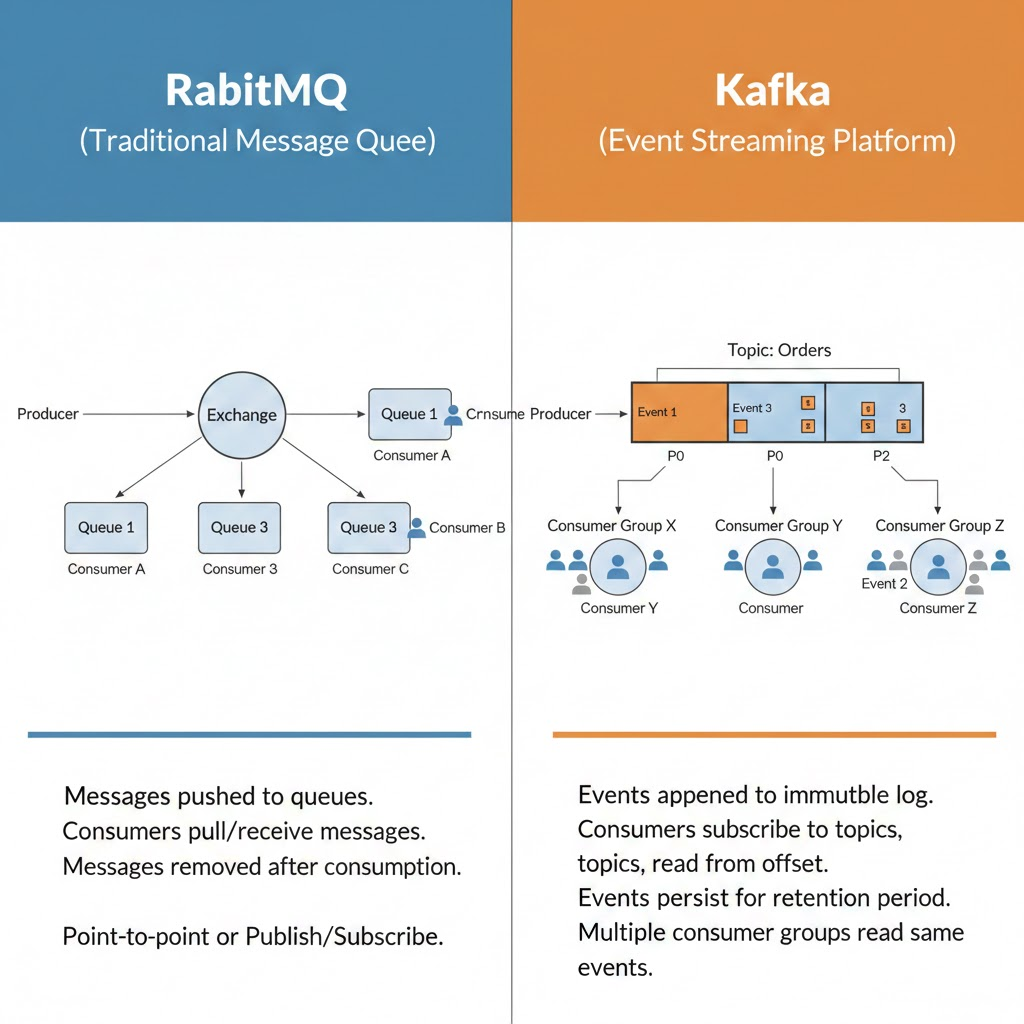
구분 RabbitMQ (메시지 큐) Kafka (이벤트 스트리밍)
| 데이터 보존 | 소비되면 삭제 | 설정한 기간 동안 영구 보존 |
| 처리 방식 | 메시지 전달 후 삭제 | 이벤트 로그로 저장 |
| 처리량 | 수천 msg/sec | 수백만 msg/sec |
| 재처리 | 어려움 | 쉬움 (Offset 이동) |
| 확장성 | 제한적 | 무한 확장 가능 |
| 사용 사례 | 작업 큐, 간단한 메시징 | 대용량 로그, 실시간 분석 |
핵심 차이:
메시지 브로커와 다르게 이벤트 브로커는 이벤트 소싱 방식이다. 카프카는 메시지가 사용되어도 사라지지 않는다.
🏗️ Kafka의 핵심 구성 요소

1️⃣ Kafka Cluster & Broker
Broker: 하나의 Kafka 서버
Kafka Cluster
├── Broker 1 (server:9092)
├── Broker 2 (server:9093)
└── Broker 3 (server:9094)
역할:
- 프로듀서로부터 메시지 수신
- 오프셋 지정
- 디스크에 저장
- 컨슈머에게 전달
하나의 카프카 서버를 브로커(Broker)라고 한다. 브로커는 프로듀서로부터 메시지를 수신하고 오프셋을 지정한 후 해당 메시지를 디스크에 저장한다.
2️⃣ Topic - 데이터의 분류
Topic: 데이터가 저장되는 논리적 카테고리
예시:
Topic: user-events
├── 로그인 이벤트
├── 로그아웃 이벤트
└── 프로필 수정 이벤트
Topic: order-events
├── 주문 생성 이벤트
├── 결제 완료 이벤트
└── 배송 시작 이벤트
토픽(Topic)은 데이터의 주제를 나타내며, 이름으로 분리된 로그입니다. 메시지를 보낼 때는 특정 토픽을 지정합니다.
3️⃣ Partition - 확장성의 핵심
Partition: 토픽을 여러 조각으로 나눈 것
Topic: user-events (3개 파티션)
Partition 0: [msg1, msg4, msg7, msg10...]
Partition 1: [msg2, msg5, msg8, msg11...]
Partition 2: [msg3, msg6, msg9, msg12...]
왜 나눌까?
✅ 병렬 처리 가능
✅ 데이터 분산 저장
✅ 높은 처리량
파티션(Partition)은 토픽은 하나 이상의 파티션으로 나누어질 수 있으며, 각 파티션은 순서가 있는 연속된 메시지의 로그입니다. 파티션은 병렬 처리를 지원하고, 데이터의 분산 및 복제를 관리합니다.
4️⃣ Offset - 메시지의 위치
Offset: 파티션 내 메시지의 고유한 순번
// 예시
Partition 0:
Offset 0: {"userId": 1, "event": "login"}
Offset 1: {"userId": 2, "event": "logout"}
Offset 2: {"userId": 3, "event": "login"}
...
Offset이 중요한 이유:
- 어디까지 읽었는지 추적
- 원하는 시점으로 되돌리기 가능
- 정확히 한 번 처리 보장
오프셋(Offset)은 특정 파티션 내의 레코드 위치를 식별하는 값입니다.
📤 Producer - 데이터를 보내는 쪽
Producer의 역할
프로듀서(Producer)는 데이터를 토픽에 보내는 역할을 하며, 메시지를 생성하고 특정 토픽으로 보냅니다.

Producer 코드 예시
// Producer 설정
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Producer 생성
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 메시지 전송
ProducerRecord<String, String> record =
new ProducerRecord<>("user-events", "user123", "login");
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("전송 성공: " + metadata.offset());
} else {
System.err.println("전송 실패: " + exception.getMessage());
}
});
producer.close();
Partitioning 전략
메시지가 어느 파티션으로 갈지 결정하는 방법:
1) Key 기반 파티셔닝
// 같은 키는 항상 같은 파티션으로!
ProducerRecord<String, String> record1 =
new ProducerRecord<>("orders", "user123", "{order1}"); // → Partition 0
ProducerRecord<String, String> record2 =
new ProducerRecord<>("orders", "user123", "{order2}"); // → Partition 0
ProducerRecord<String, String> record3 =
new ProducerRecord<>("orders", "user456", "{order3}"); // → Partition 1
결과: user123의 모든 주문은 순서대로 처리됨!
2) Round-Robin (키 없을 때)
// 키가 없으면 라운드 로빈
ProducerRecord<String, String> record =
new ProducerRecord<>("logs", null, "log message");
결과: 파티션 0 → 1 → 2 → 0 → 1 → 2 ...
📥 Consumer - 데이터를 읽는 쪽
Consumer의 역할
컨슈머(Consumer)는 토픽에서 데이터를 읽는 역할을 하며, 특정 토픽의 메시지를 가져와서(poll) 처리합니다.
Consumer 코드 예시
// Consumer 설정
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "user-event-processor");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Consumer 생성
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("user-events"));
// 메시지 읽기
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Offset: %d, Key: %s, Value: %s%n",
record.offset(), record.key(), record.value());
// 비즈니스 로직 처리
processUserEvent(record.value());
}
}
Consumer Group - 확장성의 비밀
Consumer Group: 같은 목적으로 데이터를 읽는 Consumer들의 집합
Topic: user-events (3 Partitions)
Consumer Group: analytics-team
├── Consumer 1 → Partition 0
├── Consumer 2 → Partition 1
└── Consumer 3 → Partition 2
Consumer Group: notification-team
├── Consumer 4 → Partition 0, 1, 2
핵심:
1. 같은 그룹 내에서 하나의 파티션은 하나의 컨슈머만!
2. 다른 그룹은 독립적으로 읽음
중요한 규칙:
하나의 토픽 내의 파티션 개수보다 더 많은 수의 컨슈머를 추가하는 것은 의미가 없다.
// ✅ 좋은 예
Partition 4개 : Consumer 4개 = 최대 성능!
// ❌ 나쁜 예
Partition 4개 : Consumer 5개 = 1개는 놀아요!
// ⚠️ 주의할 예
Partition 4개 : Consumer 2개 = 처리 느림
🔄 Rebalancing - 동적 할당
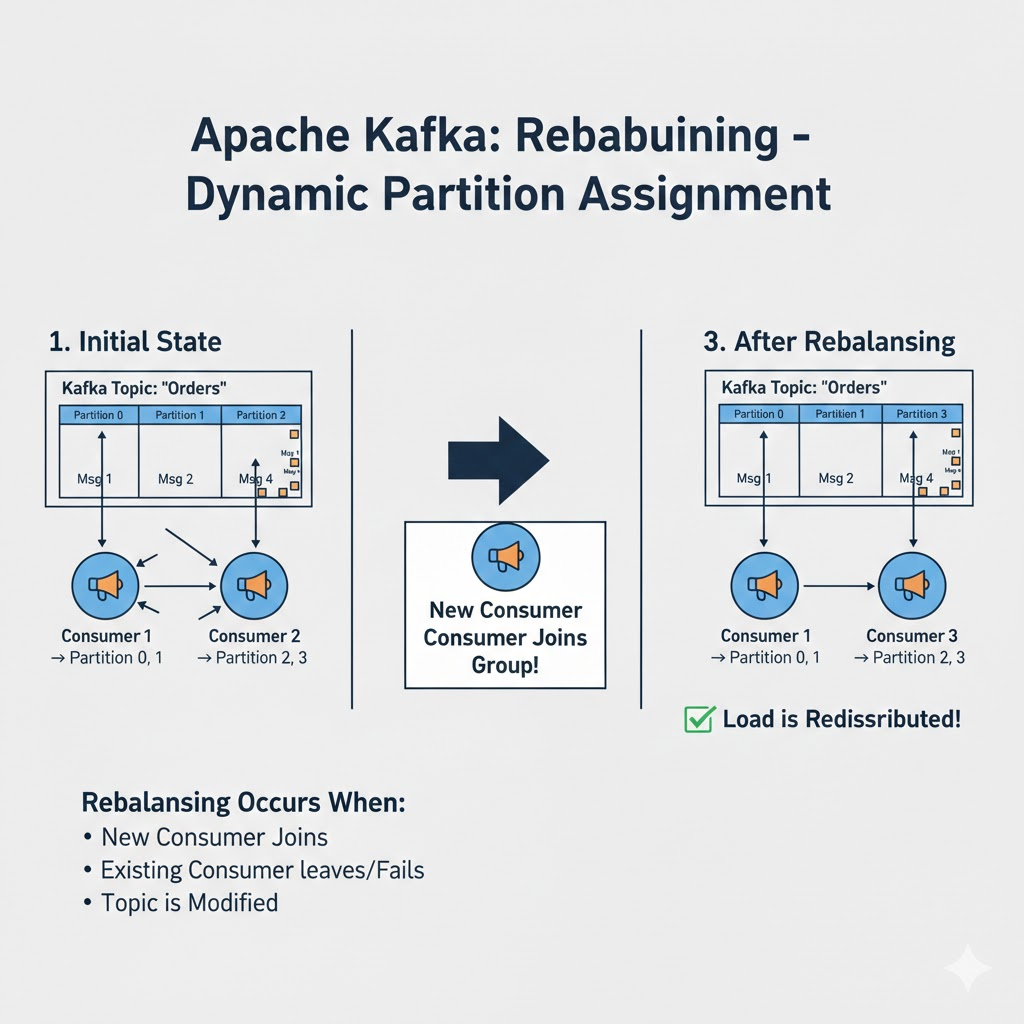
Rebalancing이란?
한 컨슈머로부터 다른 컨슈머로 파티션 소유권이 이전되는 것을 리밸런싱(Rebalancing)이라고 한다.
Rebalancing이 발생하는 경우
초기 상태:
Consumer 1 → Partition 0, 1
Consumer 2 → Partition 2, 3
🆕 Consumer 3 추가!
리밸런싱 후:
Consumer 1 → Partition 0
Consumer 2 → Partition 1
Consumer 3 → Partition 2, 3
✅ 부하가 재분배되었어요!
리밸런싱 발생 조건:
- 새로운 컨슈머 추가
- 기존 컨슈머 종료/오류
- 파티션 개수 변경
🛡️ Kafka의 내결함성 (Fault Tolerance)
Replication - 데이터 복제
Topic: orders (3 Partitions, Replication Factor: 3)
Broker 1 (Leader):
├── Partition 0 (Leader) ⭐
├── Partition 1 (Follower)
└── Partition 2 (Follower)
Broker 2:
├── Partition 0 (Follower)
├── Partition 1 (Leader) ⭐
└── Partition 2 (Follower)
Broker 3:
├── Partition 0 (Follower)
├── Partition 1 (Follower)
└── Partition 2 (Leader) ⭐
장점:
- Broker 1개 죽어도 데이터 안전!
- Leader가 죽으면 Follower가 Leader로 승격
Leader와 Follower:
producer가 메세지를 쓰고, consumer가 메세지를 읽는 건 오로지 leader가 전적으로 역할을 담당한다. 나머지 follower들은 leader와 싱크를 항상 맞춘다.
ISR (In-Sync Replicas)
ISR = Leader와 동기화된 Follower 목록
Partition 0:
- Leader: Broker 1 ✅
- ISR: [Broker 1, Broker 2, Broker 3]
만약 Broker 3이 느려지면:
- Leader: Broker 1 ✅
- ISR: [Broker 1, Broker 2]
- Out-of-sync: [Broker 3] ⚠️

💻 실무 활용 사례
1️⃣ 실시간 로그 수집
// 로그 Producer
public class LogProducer {
private final KafkaProducer<String, String> producer;
public void sendLog(String logLevel, String message) {
String logJson = String.format(
"{\"level\": \"%s\", \"message\": \"%s\", \"timestamp\": %d}",
logLevel, message, System.currentTimeMillis()
);
ProducerRecord<String, String> record =
new ProducerRecord<>("application-logs", logLevel, logJson);
producer.send(record);
}
}
// 로그 Consumer (ElasticSearch에 저장)
public class LogConsumer {
public void processLogs() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// ElasticSearch에 저장
elasticSearchClient.index("logs", record.value());
}
}
}
}
2️⃣ 이벤트 기반 마이크로서비스
// 주문 서비스 → Kafka
@Service
public class OrderService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void createOrder(Order order) {
// 주문 저장
orderRepository.save(order);
// Kafka에 이벤트 발행
String orderEvent = objectMapper.writeValueAsString(order);
kafkaTemplate.send("order-created", order.getUserId(), orderEvent);
}
}
// 알림 서비스 ← Kafka
@Service
public class NotificationService {
@KafkaListener(topics = "order-created", groupId = "notification-service")
public void handleOrderCreated(String orderEvent) {
Order order = objectMapper.readValue(orderEvent, Order.class);
// 이메일 발송
emailService.sendOrderConfirmation(order.getUserEmail());
// 푸시 알림
pushService.sendNotification(order.getUserId(), "주문이 접수되었습니다!");
}
}
// 재고 서비스 ← Kafka
@Service
public class InventoryService {
@KafkaListener(topics = "order-created", groupId = "inventory-service")
public void handleOrderCreated(String orderEvent) {
Order order = objectMapper.readValue(orderEvent, Order.class);
// 재고 차감
inventoryRepository.decreaseStock(order.getProductId(), order.getQuantity());
}
}
3️⃣ CDC (Change Data Capture)
// 데이터베이스 변경 이벤트 캡처
@Service
public class UserService {
@Transactional
public void updateUser(User user) {
// DB 업데이트
userRepository.save(user);
// Kafka에 변경 이벤트 발행
UserChangeEvent event = new UserChangeEvent(
user.getId(),
"UPDATE",
objectMapper.writeValueAsString(user)
);
kafkaTemplate.send("user-changes", user.getId().toString(), event);
}
}
// 검색 엔진 동기화
@Service
public class SearchSyncService {
@KafkaListener(topics = "user-changes", groupId = "search-sync")
public void syncToElasticSearch(UserChangeEvent event) {
if (event.getType().equals("UPDATE")) {
User user = objectMapper.readValue(event.getData(), User.class);
elasticSearchClient.update("users", user.getId(), user);
}
}
}
📊 Kafka 설정 Best Practices

Producer 설정
Properties props = new Properties();
// 필수 설정
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092,kafka3:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 성능 최적화
props.put("acks", "all"); // 모든 복제본이 받을 때까지 대기
props.put("retries", 3); // 실패 시 재시도 횟수
props.put("batch.size", 16384); // 배치 크기 (바이트)
props.put("linger.ms", 10); // 배치 대기 시간 (밀리초)
props.put("compression.type", "snappy"); // 압축 타입
// 멱등성 보장
props.put("enable.idempotence", "true"); // 중복 방지
Consumer 설정
Properties props = new Properties();
// 필수 설정
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092,kafka3:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Offset 관리
props.put("enable.auto.commit", "false"); // 수동 커밋
props.put("auto.offset.reset", "earliest"); // 처음부터 읽기
// 성능 최적화
props.put("fetch.min.bytes", 1024); // 최소 페치 크기
props.put("max.poll.records", 500); // 한 번에 가져올 레코드 수
💡 오늘 나는 무엇을 배웠는가
1. Kafka는 메시지 큐가 아니다
처음에는 "Kafka = RabbitMQ 같은 메시지 큐"라고 생각했는데, 완전히 다른 개념이더라고요!
메시지 큐 (RabbitMQ):
✉️ 편지를 전달하면 사라짐
→ 일회성 작업에 적합
이벤트 스트리밍 (Kafka):
📚 모든 이벤트를 기록하고 보관
→ 재처리, 분석, 감사에 적합
2. 파티션 개수 = 성능의 핵심
파티션 1개:
- Consumer 1개만 처리
- 처리량: 100 msg/sec
파티션 10개:
- Consumer 10개 병렬 처리
- 처리량: 1,000 msg/sec
파티션 100개:
- Consumer 100개 병렬 처리
- 처리량: 10,000 msg/sec
파티션을 잘 설계하면 성능이 100배 차이!
3. Offset이 정말 중요하다
Offset 덕분에:
✅ 정확히 한 번만 처리 (Exactly Once)
✅ 에러 발생 시 재처리
✅ 과거 데이터 다시 읽기
✅ 여러 Consumer Group 독립 처리
이게 없었으면 Kafka는 그냥 메시지 큐!
😊 좋았던 점 & 😅 아쉬웠던 점
좋았던 점
👍 실무 중심 수업
단순히 "Kafka는 이렇다"가 아니라 "실제로 이렇게 쓴다"를 배워서 좋았어요. 특히 우아한형제들 사례가 인상 깊었습니다!
👍 직접 실습
Docker로 Kafka Cluster 띄우고, Producer/Consumer 코드 직접 작성해보니 개념이 확실히 잡혔어요.
👍 성능 차이 체감
파티션 1개 vs 10개로 실습했을 때 처리 속도 차이가 명확하게 보여서 놀라웠어요!
아쉬웠던 점
😢 Zookeeper 개념
Kafka 3.0부터는 Zookeeper 없이도 된다고 하는데, 아직 많은 회사가 Zookeeper를 쓰고 있어서 헷갈려요.
😢 실습 시간 부족
Kafka Streams, Kafka Connect 등 고급 기능도 배우고 싶었는데 시간이 부족했어요.
😢 운영 관련 내용
실제 프로덕션 환경에서 Kafka를 어떻게 모니터링하고 관리하는지도 알고 싶었습니다.
🤔 어려웠던 점과 해결
문제 1: Consumer Group 개념

"같은 그룹 내에서 한 파티션은 한 컨슈머"라는 게 처음엔 이해가 안 됐어요.
해결: 직접 그림 그려보니 이해됨!
파티션 3개, 컨슈머 2개:
Consumer 1: 파티션 0, 1
Consumer 2: 파티션 2
파티션 3개, 컨슈머 4개:
Consumer 1: 파티션 0
Consumer 2: 파티션 1
Consumer 3: 파티션 2
Consumer 4: 놀아요! ❌
문제 2: Offset Commit 시점
언제 커밋해야 하는지 헷갈렸어요.
해결: 처리 완료 후 수동 커밋이 가장 안전!
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try {
// 처리
processRecord(record);
// ✅ 처리 성공 후 커밋
consumer.commitSync();
} catch (Exception e) {
// ❌ 실패하면 커밋 안 함 → 재처리
log.error("처리 실패", e);
}
}
}
문제 3: 파티션 키 선택
어떤 키를 사용해야 순서가 보장되는지 몰랐어요.
해결: 순서가 중요한 단위로 키 설정!
// ✅ 사용자별 순서 보장
record = new ProducerRecord<>("orders", userId, orderData);
// ✅ 상품별 순서 보장
record = new ProducerRecord<>("inventory", productId, inventoryData);
// ❌ 순서 보장 안 됨
record = new ProducerRecord<>("logs", null, logData);
🎓 나만의 학습 팁
1. Docker로 로컬 환경 구축
# docker-compose.yml
version: '3'
services:
kafka:
image: confluentinc/cp-kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
zookeeper:
image: confluentinc/cp-zookeeper:latest
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
2. 개념을 그림으로 정리
복잡한 개념은 직접 그림으로 그려서 Notion에 정리했어요. 특히 Partition, Offset, Consumer Group 관계를 그림으로 그리니까 이해가 쉬웠습니다!
3. 실습 프로젝트 아이디어
프로젝트 1: 실시간 주문 시스템
- Producer: 주문 생성
- Consumer 1: 알림 발송
- Consumer 2: 재고 차감
- Consumer 3: 로그 저장
프로젝트 2: 로그 수집 시스템
- Producer: 애플리케이션 로그
- Consumer: ElasticSearch 저장
프로젝트 3: 이벤트 소싱
- 모든 상태 변경을 이벤트로 저장
- 언제든 과거 상태 재현 가능
🚀 다음 학습 목표
📌 단기 목표 (이번 주)
✓ Kafka Streams로 실시간 데이터 처리 구현
✓ Kafka Connect로 DB 연동 실습
✓ 개인 프로젝트에 Kafka 적용해보기
📌 중기 목표 (이번 달)
✓ Schema Registry로 데이터 스키마 관리
✓ Kafka 모니터링 도구 (Kafka Manager) 사용
✓ 실제 운영 환경 설정 Best Practice 학습
📌 장기 목표 (부트캠프 기간)
✓ 포트폴리오에 Kafka 활용 프로젝트 추가
✓ 대용량 트래픽 처리 경험 쌓기
✓ 이벤트 기반 마이크로서비스 아키텍처 구축
🎬 마치며
오늘 Kafka를 배우기 전에는 "메시지 큐 하나 더 배우는 건가?"라고 생각했는데, 전혀 다른 차원의 기술이더라고요!
Kafka는 단순한 메시지 전달이 아니라, 데이터의 흐름 자체를 관리하는 플랫폼이라는 걸 깨달았습니다.
"메시지는 사라지지만, 이벤트는 기록된다"
특히 실무에서 마이크로서비스 간 통신, 실시간 로그 처리, 대용량 데이터 파이프라인 등에서 Kafka가 왜 필수인지 이해하게 되었어요.
앞으로 개인 프로젝트에서도 Kafka를 적용해서, "대용량 트래픽을 Kafka로 처리해본 경험"을 쌓아야겠습니다! 💪
여러분도 Kafka, 한번 도전해보세요. 분명 백엔드 개발자로서 한 단계 성장하는 계기가 될 거예요! 🚀
📚 참고 자료
공식 문서
기술 블로그
- 우아한형제들 기술블로그 - 우리 팀은 카프카를 어떻게 사용하고 있을까
- Apache Kafka 간략하게 살펴보기 - Medium
- 10분안에 알아보는 Kafka - Medium
- 카프카가 무엇이고, 왜 사용하는 것 일까? - Hudi Blog
- Kafka 이해하기 - Medium